![]()
|
About This Site : Getting Started | Contact | About This Project | How To | Honors | Credits | Tech Info Overview Technology Page Contents: Introduction Dialog between the lead technical developer and other team members was important at an early stage in the development of this siteas soon as an outline of the content and the basic design approach had been established. A thorough understanding of the intended design and content helped determine what technologies should be used. And, in turn, the technical practicalities and decisions helped inform the design possibilities, the content structure and the overall structure of the site. We knew from the outset that this would be an extensive siteextensive textual and image content and a core of interactive scenes. We also know we would feature a collection of many artifacts. All of these things pointed toward sophisticated technologies for the site including databases and XML. Each of these seem indespensable to a site of this scope, so we will discuss those first. We will also discuss the Flash we used for our interactive scenes. Lastly we will cover the web application framework we used to knit all of the pieces together. Database Design In addition to the collection, we also stored glossary terms and bibliography entries in database tables. However the collection of artifacts, one of the key features of the site, required the most planning and attention. The task of defining fields for the collection required close collaboration between the technologist, the designer and the content folks. We needed to identify what pieces of information would be displayed on the pages, what pieces were needed by the curators and production people independent of display and lastly, what would be required by the web application itself. We had two points of reference as we defined the fields: the museum's pre-existing database for their large collection featured on the American Centuries site and the mandate in our IMLS grant to adhere to and promote standards aimed at information exchange. We identified the Dublin Core Metadata Initiative (http://dublincore.org/) as the prevailing standard for museum collections. As it turned out, the content of most of the museum's existing fields paralleled the Dublin Core fieldswe adopted the Dublin Core terminology for both the curatorial and display fields where relevant. (See the data entry form in the section below for a full list of fields.) For indexing within the web application we used auto-generated integers, while the curators referred to ascension numbers for unique identification. As far as the database technology itself, the museum was already using Microsoft SQL Server for American Centuries. We wanted to share the same server, so we went ahead and used that technology. We could have worked with any full-featured databasewe have successfully used the open source MySQL on a number of projects. Data Entry Each type of content, artifacts, glossary, bibliography and so on, had its own comprehensive list. Besides providing an entry point for content editing, each entry also linked to a preview of the finished page in the site. The list was also used to track production progress. 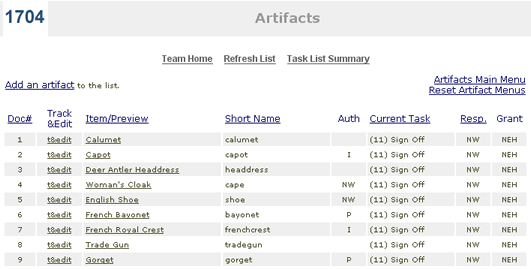 Selecting the edit link brings up a text entry form for editing all of the fields. In the artifact form below there is a section for Content and a section for Tracking. The last few fields of content are labeled as Non-Display. Some fields are presented as checkboxes, such as whether or not this artifact receives a "special feature" icon or not. 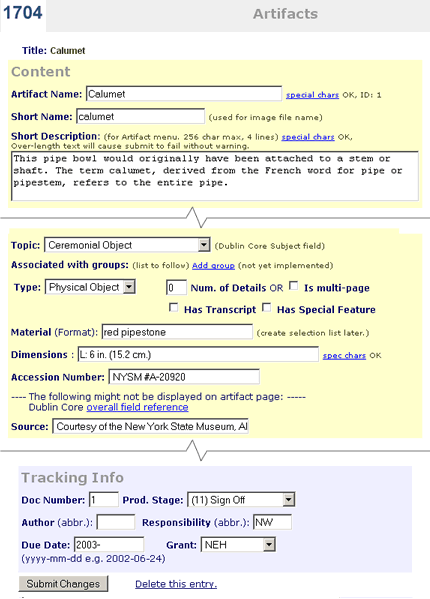 After submitting the changes the editor can use the preview link to bring up the real page in the site reflecting the recent changes. XML Implementation While it would be possible to write this kind of material directly into HTML we believe this to be unsustainable. The writer would be encumbered by the HTML tags and the designer would be encumbered by all of the text and the frequent versions as the text is rewritten and corrected, and each would be encumbered by the need to coordinate with the other. Overall changes in design, inevitable during development, would become extremely tedious. We wanted to follow the best practice of keeping content separate from display. We felt it was well worth the extra overhead to store the content in XML. We created XML schemas for character narratives and background essays that defined sections, headings, subheadings, images, captions and page navigation such as links to glossary terms, maps and other essays. Following is a small excerpt from the beginning of the XML for a character narrative:
<person>
Data Entry To accomplish this we created templates in Altova's XMLSpy that worked with Altova's stand-alone editor called Authentic. With that editor and the appropriate template in place editing became as WYSIWYG as a word processor. Additionally there were boxes for entering the structured information required for each link that appeared within the text. 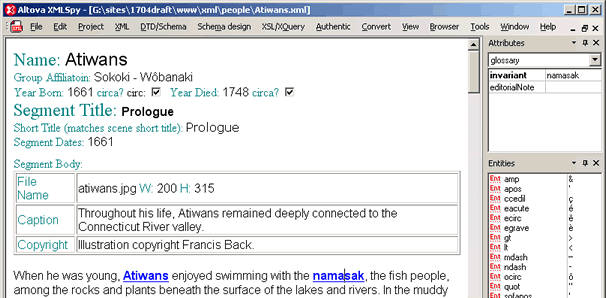 The XML files were checked in and out of the server using Dreamweaver. That product has a check-in and out feature that prevents two people from changing the same file at the same time. Once a file was posted the changes were immediately reflected in the online preview accessed through the tracking lists, or within the site itself. Display
might be transformed to the following HTML:
You'll notice that we're also using CSS. The syntax of XSL itself is a bit arcane and is beyond the scope of this document. We used Apache Xalan (http://xml.apache.org/xalan-j/ ) behind the scenes to accomplish these transformations in real-time. Because this is fairly processor-intensive we implemented a caching schemethe transformation happens once, then on subsequent visits to the page the content is delivered from server memory. Flash The shared scenes contain extensive text in addition to the images. In keeping with our policy of separating content from display, we stored text in XML files outside of Flash. This was doubly beneficial since we also wanted to present plain text versions of the shared scenesa single XML file could be transformed either for use in Flash or to plain HTML. We channeled the content from XML to Flash using an approach that involved several steps. We wrote XSL that transformed the XML to a set of Action Script arrays that could be read by Flash:
For each set of changes we would then need to re-compile the Flash. This was the one case where the editors did not see there changes in real-time. However, at the beginning of the authoring process we compiled the changes and additions often so that the authors could get acclimated to seeing their content in this interactive formata format very different from a Word document. Web Application Framework A number of base technologies could be used to knit together the elements described above. We wanted a cross-platform solution that would run on our existing Windows server, but one that could be moved, if necessary, to a commercial server that might be running UNIX or Linux. We therefore excluded Microsoft .Net solutions. We also thought that our scope, sophisticated needs and desire for long term maintenance would push the limits of PHP. We had experience with Java servlet technology from the American Centuries site and other projects, so this was a natural choice. Java servlets represent a mature, open-source, cross-platform, industrial-strength technology. It does present a fairly high threshold for entrya lengthy learning curve for the uninitiated. So an experienced Java programmer is required in the mix. For legacy and other reasons some institutions will make choices different from what we describe here. On top of the Java servlet technology, and new to us for this project, we chose to use the Apache Struts web application framework ( http://struts.apache.org/ ). A framework such as this takes care of a lot of groundwork allowing the developer to focus on the unique aspects of a given site. Many developers are using Struts so many discussion and a lot of help are available online. In the discussions of database and XML usage above we have mentioned the benefits of keeping content separate from display. The Struts framework helps additionally by keeping the flow of control separate from both the content and the display. This is known as the Model-View-Control approach. For controlling the flow (navigation) Struts provides a configuration file that associates URLs with content and with the pages that display that content. Because of this configuration file the site can be expanded by adding URLs and page names without touching the code. Of course the content has to be written and any new display has to be created, but it's a big plus not to have to go back into the programming cycle for every change. The actual display is accomplished with tags inserted into the JSPJava Server Pages. There is no programming contained in the pagesa designer is able make changes to these tags as well as to the surrounding plain HTML. |
![]()
About This Site
Resources
Glossary
Teachers' Guide
Site Map
How To
© 2020 PVMA / Memorial Hall Museum